Quick start for NPH sample size and power
Keaven M. Anderson
Source:vignettes/gsDesign2.Rmd
gsDesign2.RmdPlease see https://merck.github.io/gsDesign2/articles/ for the full
set of articles.
This vignette is only a quick start guide.
Overview
We provide simple examples for use of the gsDesign2 package for deriving fixed and group sequential designs under non-proportional hazards. The piecewise model for enrollment, failure rates, dropout rates and changing hazard ratio over time allow great flexibility in design assumptions. Users are encouraged to suggest features that would be of immediate and long-term interest to add.
Topics included here are:
- Packages required and how they are used.
- Specifying enrollment rates.
- Specifying failure and dropout rates with possibly changing hazard ratio over time.
- Deriving a fixed design with no interim analysis.
- Simple boundary specification for group sequential design.
- Deriving a group sequential design under non-proportional hazards.
- Displaying design properties.
- Design properties under alternate assumptions.
- Differences from gsDesign.
- Future enhancement priorities.
All of these items are discussed briefly to enable a quick start for early adopters while also suggesting the ultimate possibilities that the software enables. Finally, while the final section provides current enhancement priorities, potential topic-related enhancements are discussed throughout the document.
Packages used
- The gsDesign package is used as a check for results under proportional hazards as well as a source from deriving bounds using spending functions.
- The gsDesign2 package provides
- computations to compute expected event accumulation and average hazard ratio over time; these are key inputs to the group sequential distribution parameters.
- implement group sequential distribution theory under non-proportional hazards and to derive a wide variety of boundary types for group sequential designs.
- The simtrial package is used to verify design properties using simulation.
Enrollment rates
Piecewise constant enrollment rates are input in a tabular format. Here we assume enrollment will ramp-up with \(25\%\), \(50\%\), and \(75\%\) of the final enrollment rate for \(2\) months each followed by a steady state \(100\%\) enrollment for another \(6\) months. The rates will be increased later to power the design appropriately. However, the fixed enrollment rate periods will remain unchanged.
enroll_rate <- define_enroll_rate(
duration = c(2, 2, 2, 6),
rate = (1:4) / 4
)
enroll_rate |> gt()| stratum | duration | rate |
|---|---|---|
| All | 2 | 0.25 |
| All | 2 | 0.50 |
| All | 2 | 0.75 |
| All | 6 | 1.00 |
Failure and dropout rates
Constant failure and dropout rates are specified by study period and stratum; we consider a single stratum here. A hazard ratio is provided for treatment/control hazard rate for each period and stratum. The dropout rate for each period is assumed the same for each treatment group; this restriction could be eliminated in a future version, if needed. Generally, we take advantage of the identity for an exponential distribution with median \(m\), the corresponding failure rate \(\lambda\) is
\[\lambda = \log(2) / m.\]
We consider a control group exponential time-to-event with a \(12\) month median. We assume a hazard ratio of \(1\) for \(4\) months, followed by a hazard ratio of \(0.6\) thereafter. Finally, we assume a low \(0.001\) exponential dropout rate per month for both treatment groups.
median_surv <- 12
fail_rate <- define_fail_rate(
duration = c(4, Inf),
fail_rate = log(2) / median_surv,
hr = c(1, .6),
dropout_rate = .001
)
fail_rate |> gt()| stratum | duration | fail_rate | dropout_rate | hr |
|---|---|---|---|---|
| All | 4 | 0.05776227 | 0.001 | 1.0 |
| All | Inf | 0.05776227 | 0.001 | 0.6 |
Fixed design
Under the above enrollment, failure and dropout rate assumptions we now derive sample size for a trial targeted to complete in 36 months with no interim analysis, \(90\%\) power and \(2.5\%\) Type I error.
alpha <- .025
beta <- .1 # 1 - targeted power
d <- fixed_design_ahr(
enroll_rate = enroll_rate, # Relative enrollment rates
fail_rate = fail_rate, # Failure rates from above
alpha = alpha, # Type I error
power = 1 - beta, # Type II error = 1 - power
study_duration = 36 # Planned trial duration
)A quick summary of the targeted sample size is obtained below. Note
that you would normally round up N up to an even number and
Events to the next integer.
| Fixed Design under AHR Method1 | |||||||
| Design | N | Events | Time | AHR | Bound | alpha | Power |
|---|---|---|---|---|---|---|---|
| Average hazard ratio | 433.6922 | 315.2547 | 36 | 0.6934128 | 1.959964 | 0.025 | 0.9 |
| 1 Power computed with average hazard ratio method. | |||||||
The enrollment rates for each period have been increased proportionately to size the trial for the desired properties; the duration for each enrollment rate has not changed.
d$enroll_rate |> gt()| stratum | duration | rate |
|---|---|---|
| All | 2 | 12.04701 |
| All | 2 | 24.09401 |
| All | 2 | 36.14102 |
| All | 6 | 48.18802 |
Group sequential design
We will not go into detail for group sequential designs here. In brief, however, a sequence of tests \(Z_1, Z_2,\ldots, Z_K\) that follow a multivariate normal distribution are performed to test if a new treatment is better than control (Jennison and Turnbull (1999)). We assume \(Z_k > 0\) is favorable for the experimental treatment. Generally Type I error for this set of tests will be controlled under the null hypothesis of no treatment difference by a sequence of bounds \(b_1, b_2,\ldots,b_K\) such that for a chosen Type I error \(\alpha > 0\) we have
\[ \alpha = 1 - P_0(\cap_{k=1}^K Z_k < b_k) \] Where \(P_0()\) refers to a probability under the null hypothesis. This is referred to as a non-binding bound since it is assumed the trial will not be stopped early for futility if some \(Z_k\) is small.
Simple efficacy bound definition
Lan and DeMets (1983) developed the spending function method for deriving group sequential bounds. This involves use of a non-decreasing spending function \(f(t)\) for \(t \geq 0\) where \(f(0)=0\) and \(f(t)=\alpha\) for \(t \geq 1\). Suppose for \(K>0\) analyses are performed when proportion \(t_1< t_2 <\ldots t_K=1\) of some planned statistical information (e.g., proportion of planned events for a time-to-event endpoint trial for proportion of observations for a binomial or normal endpoint). Bounds through the first \(k\) analyses \(1\leq k\leq K\) are recursively defined by the spending function and the multivariate normal distribution to satisfy
\[ f(t_k) = 1 - P_0(\cap_{j=1}^k Z_j < b_j). \] For this quick start, we will only illustrate this type of efficacy bound.
Perhaps the most common spending function for this approach is the Lan and DeMets (1983) approximation to the O’Brien-Fleming bound with
\[ f(t) = 2-2\Phi\left(\frac{\Phi^{-1}(1-\alpha/2)}{t^{1/2}}\right). \]
Suppose \(K=3\) and \(t_1=0.5\), \(t_2 = 0.75\), \(t_3 = 1\). We can use the assumptions above for a group sequential design with only an efficacy bound using the Lan-DeMets O’Brien-Fleming spending function for \(\alpha = 0.025\) with
design1s <- gs_design_ahr(
alpha = alpha,
beta = beta,
enroll_rate = enroll_rate,
fail_rate = fail_rate,
analysis_time = c(16, 26, 36), # Calendar time of planned analyses
upper = gs_spending_bound, # Spending function bound for efficacy
upar = list(sf = gsDesign::sfLDOF, total_spend = 0.025), # Specify spending function and total Type I error
lower = gs_b, lpar = rep(-Inf, 3), # No futility bound
info_scale = "h0_h1_info"
)Bounds at the 3 analyses are as follows. Note that expected sample
size at time of each data cutoff for analysis is also here in
N. We filter on the upper bound so that lower bounds with
Z = -Inf are not shown.
design1s |>
summary() |>
as_gt(
title = "1-sided group sequential bound using AHR method",
subtitle = "Lan-DeMets spending to approximate O'Brien-Fleming bound"
)| 1-sided group sequential bound using AHR method | |||||
| Lan-DeMets spending to approximate O'Brien-Fleming bound | |||||
| Bound | Z | Nominal p1 | ~HR at bound2 |
Cumulative boundary crossing probability
|
|
|---|---|---|---|---|---|
| Alternate hypothesis | Null hypothesis | ||||
| Analysis: 1 Time: 16 N: 449 Events: 159.3 AHR: 0.81 Information fraction: 0.49 | |||||
| Efficacy | 3.00 | 0.0013 | 0.6213 | 0.0511 | 0.0013 |
| Analysis: 2 Time: 26 N: 449 Events: 262.6 AHR: 0.72 Information fraction: 0.8 | |||||
| Efficacy | 2.26 | 0.0120 | 0.7570 | 0.6580 | 0.0125 |
| Analysis: 3 Time: 36 N: 449 Events: 326.4 AHR: 0.69 Information fraction: 1 | |||||
| Efficacy | 2.03 | 0.0212 | 0.7988 | 0.9000 | 0.0250 |
| 1 One-sided p-value for experimental vs control treatment. Value < 0.5 favors experimental, > 0.5 favors control. | |||||
| 2 Approximate hazard ratio to cross bound. | |||||
gsDesign to replicate above bounds (this will not replicate sample size).
x <- gsDesign(k = 3, test.type = 1, timing = design1s$analysis$info_frac, sfu = sfLDOF)
cat(
"gsDesign\n Upper bound: ", x$upper$bound,
"\n Cumulative boundary crossing probability (H0): ", cumsum(x$upper$prob[, 1]),
"\n Timing (IF): ", x$timing,
"\ngs_design_ahr\n Upper bound: ", design1s$bound$z,
"\n Cumulative boundary crossing probability (H0): ", design1s$bound$probability0,
"\n Timinng (IF): ", design1s$analysis$info_frac,
"\n"
)
#> gsDesign
#> Upper bound: 3.013804 2.264946 2.027236
#> Cumulative boundary crossing probability (H0): 0.00128997 0.01217731 0.025
#> Timing (IF): 0.4850799 0.7993622 1
#> gs_design_ahr
#> Upper bound: 3.003506 2.256138 2.028823
#> Cumulative boundary crossing probability (H0): 0.001334442 0.01246455 0.025
#> Timinng (IF): 0.4850799 0.7993622 1Two-sided testing
We will consider both symmetric and asymmetric 2-sided designs.
Symmetric 2-sided bounds
Our first 2-sided design is a symmetric design.
design2ss <- gs_design_ahr(
alpha = alpha,
beta = beta,
enroll_rate = enroll_rate,
fail_rate = fail_rate,
analysis_time = c(16, 26, 36), # Calendar analysis times
upper = gs_spending_bound,
upar = list(sf = gsDesign::sfLDOF, total_spend = 0.025),
lower = gs_spending_bound,
lpar = list(sf = gsDesign::sfLDOF, total_spend = 0.025),
h1_spending = FALSE # This specifies futility testing with spending under NULL
)Design bounds are confirmed with:
design2ss |>
summary() |>
as_gt(
title = "2-sided symmetric group sequential bound using AHR method",
subtitle = "Lan-DeMets spending to approximate O'Brien-Fleming bound"
)| 2-sided symmetric group sequential bound using AHR method | |||||
| Lan-DeMets spending to approximate O'Brien-Fleming bound | |||||
| Bound | Z | Nominal p1 | ~HR at bound2 |
Cumulative boundary crossing probability
|
|
|---|---|---|---|---|---|
| Alternate hypothesis | Null hypothesis | ||||
| Analysis: 1 Time: 16 N: 449 Events: 159.3 AHR: 0.81 Information fraction: 0.49 | |||||
| Futility | -3.00 | 0.9987 | 1.6096 | 0.0000 | 0.0013 |
| Efficacy | 3.00 | 0.0013 | 0.6213 | 0.0511 | 0.0013 |
| Analysis: 2 Time: 26 N: 449 Events: 262.6 AHR: 0.72 Information fraction: 0.8 | |||||
| Futility | -2.26 | 0.9880 | 1.3211 | 0.0000 | 0.0125 |
| Efficacy | 2.26 | 0.0120 | 0.7570 | 0.6580 | 0.0125 |
| Analysis: 3 Time: 36 N: 449 Events: 326.4 AHR: 0.69 Information fraction: 1 | |||||
| Futility | -2.03 | 0.9788 | 1.2518 | 0.0000 | 0.0250 |
| Efficacy | 2.03 | 0.0212 | 0.7988 | 0.9000 | 0.0250 |
| 1 One-sided p-value for experimental vs control treatment. Value < 0.5 favors experimental, > 0.5 favors control. | |||||
| 2 Approximate hazard ratio to cross bound. | |||||
The bounds can be plotted easily:
ggplot(
data = design2ss$analysis |> left_join(design2ss$bound, by = "analysis"),
aes(x = event, y = z, group = bound)
) +
geom_line(aes(linetype = bound)) +
geom_point() +
ggtitle("2-sided symmetric bounds with O'Brien-Fleming-like spending")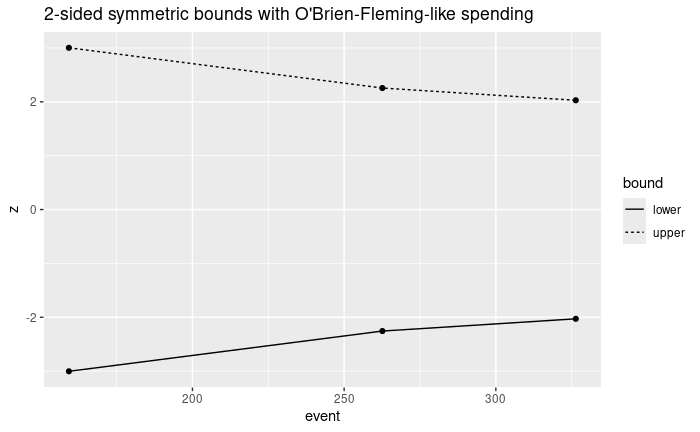
Asymmetric 2-sided bounds
Asymmetric 2-sided designs are more common than symmetric since the objectives of the two bounds tend to be different. There is often caution to analyze early for efficacy or to use other than a conservative bound; both of these principles have been used with the example designs so far. Stopping when there is a lack of benefit for experimental treatment over control or for an overt indication of an unfavorable trend generally might be examined early and bounds be less stringent. We will add an early futility analysis where if there is a nominal 1-sided p-value of \(0.05\) in the wrong direction (\(Z=\Phi^{-1}(0.05)\) after 30% or \(50\%\) of events have accrued. This might be considered a disaster check. After this point in time, there may not be a perceived need for further futility analysis. For efficacy, we add an infinite bound at this first interim analysis.
design2sa <- gs_design_ahr(
alpha = alpha,
beta = beta,
enroll_rate = enroll_rate,
fail_rate = fail_rate,
analysis_time = c(12, 16, 26, 36),
upper = gs_spending_bound,
upar = list(sf = gsDesign::sfLDOF, total_spend = 0.025), # Same efficacy bound as before
test_lower = c(FALSE, TRUE, TRUE, TRUE), # Only test efficacy after IA1
lower = gs_b,
lpar = c(rep(qnorm(.05), 2), -Inf, -Inf) # Fixed lower bound at first 2 analyses
)We now have a slightly larger sample size to account for the possibility of an early futility stop. Bounds are now:
design2sa |>
summary() |>
as_gt(
title = "2-sided asymmetric group sequential bound using AHR method",
subtitle = "Lan-DeMets spending to approximate O'Brien-Fleming bound
for efficacy, futility disaster check at IA1, IA2 only"
)| 2-sided asymmetric group sequential bound using AHR method | |||||
| Lan-DeMets spending to approximate O'Brien-Fleming bound for efficacy, futility disaster check at IA1, IA2 only | |||||
| Bound | Z | Nominal p1 | ~HR at bound2 |
Cumulative boundary crossing probability
|
|
|---|---|---|---|---|---|
| Alternate hypothesis | Null hypothesis | ||||
| Analysis: 1 Time: 12 N: 461.6 Events: 100 AHR: 0.88 Information fraction: 0.3 | |||||
| Futility | -1.64 | 0.9500 | 1.3896 | 0.0115 | 0.0500 |
| Efficacy | 3.94 | 0.0000 | 0.4545 | 0.0005 | 0.0000 |
| Analysis: 2 Time: 16 N: 461.6 Events: 163.7 AHR: 0.81 Information fraction: 0.49 | |||||
| Futility | -1.64 | 0.9500 | 1.2932 | 0.0119 | 0.0763 |
| Efficacy | 3.01 | 0.0013 | 0.6250 | 0.0496 | 0.0013 |
| Analysis: 3 Time: 26 N: 461.6 Events: 270 AHR: 0.72 Information fraction: 0.8 | |||||
| Efficacy | 2.26 | 0.0120 | 0.7598 | 0.6677 | 0.0125 |
| Analysis: 4 Time: 36 N: 461.6 Events: 335.5 AHR: 0.69 Information fraction: 1 | |||||
| Efficacy | 2.03 | 0.0212 | 0.8013 | 0.9000 | 0.0250 |
| 1 One-sided p-value for experimental vs control treatment. Value < 0.5 favors experimental, > 0.5 favors control. | |||||
| 2 Approximate hazard ratio to cross bound. | |||||