Average hazard ratio and sample size under non-proportional hazards
Keaven M. Anderson
Source:vignettes/articles/story-ahr-under-nph.Rmd
story-ahr-under-nph.RmdIntroduction
This document demonstrates applications of the average hazard ratio
concept in the design of fixed designs without interim analysis.
Throughout we consider a 2-arm trial with an experimental and control
group and a time-to-event endpoint. Testing for differences between
treatment groups is performed using the stratified logrank test. In the
above setting, the gsDesign2::ahr() routine provides an
average hazard ratio that can be used for sample size using the function
gsDesign::nSurv(). The approach assumes piecewise constant
enrollment rates and piecewise exponential failure rates with the option
of including multiple strata. This approach allows the flexibility to
approximate a wide variety of scenarios. We evaluate the approximations
used via simulation using the simtrial package; we
specifically provide a simulation routine so that any changes specified
by the user should be easily incorporated. We consider both
non-proportional hazards for a single stratum and multiple strata with
different underlying proportional hazards assumptions.
There are two things to note regarding differences between
simtrial::sim_fixed_n() and
gsDesign2::ahr():
-
simtrial::sim_fixed_n()is less flexible in that it requires all strata are enrolled at the same relative rates throughout the trial whereasgsDesign2::ahr()allows, for example, enrollment to start or stop at different times in different strata. In this document, we use the more restrictive parameterization ofsimtrial::sim_fixed_n()so that we can confirm the asymptotic sample size approximation based ongsDesign2::ahr()by simulation. -
simtrial::sim_fixed_n()provides more flexibility in test statistics used thangsDesign2::ahr()as documented in the pMaxCombo vignette demonstrating use of Fleming-Harrington weighted logrank tests and combinations of such tests.
Document organization
This vignette is organized as follows:
- Two non-proportional hazards examples are introduced for fixed
sample size approximation, one with a single stratum and one with two
strata.
- The single stratum design assumes a delayed treatment benefit.
- The stratified example assumes different proportional hazards in 3 strata.
- Each of these examples have the following subsections:
- Description of the design scenario.
- Deriving an average hazard ratio.
- Deriving sample size based on average hazard ratio.
- Computing and plotting the average hazard ratio as a function of time.
- Simulation to verify that the sample size approximation provides the targeted power.
Each simulation is done with data cutoff performed in 5 different ways:
- Based on targeted trial duration
- Based on targeted minimum follow-up duration only
- Based on targeted event count only
- Based on the maximum of targeted event count and targeted trial duration
- Based on the maximum of targeted event count and targeted minimum follow-up
The method based on waiting to achieve targeted event count and targeted minimum follow-up appears to be both practical and to provide the targeted power.
Initial setup
We begin by setting two parameters that will be used throughout in simulations used to verify accuracy of power approximations; either could be customized for each simulation. First, we set the number of simulations to be performed. You can increase this to improve accuracy of simulation estimates of power.
nsim <- 1000Simulations using the simtrial::sim_fixed_n() routine
below use blocked randomization. We set that here and do not change for
individual simulations. Based on balanced randomization in
block we set the randomization ratio of experimental to
control to 1.
We load packages needed below.
- gsDesign is used for its implementation of the Schoenfeld (1981) approximation to compute the number of events required to power a trial under the proportional hazards assumption.
- dplyr and tibble to work with tabular data and the ‘data wrangling’ approach to coding.
- simtrial to enable simulations.
-
survival to enable Cox proportional hazards
estimation of the (average) hazard ratio for each simulation to compare
with the approximation provided by the
gsDesign2::ahr()routine that computes an expected average hazard ratio for the trial (Kalbfleisch and Prentice (1981), Schemper et al. (2009)). - Hidden underneath this is the
gsDesign2::eEvents_df()routine that provides expected event counts for each period and stratum where the hazard ratio differs. This is the basic calculation used in thegsDesign2::ahr()routine.
Single stratum non-proportional hazards example
Design scenario
We set up the first scenario design parameters. Enrollment ramps up over the course of the first 4 months follow-up by a steady state enrollment thereafter. This will be adjusted proportionately to power the trial later. The control group has a piecewise exponential distribution with median 9 for the first 3 months and 18 thereafter. The hazard ratio of the experimental group versus control is 1 for the first 3 months followed by 0.55 thereafter.
# Note: this is done differently for multiple strata; see below!
enroll_rate <- define_enroll_rate(
duration = c(2, 2, 10),
rate = c(3, 6, 9)
)
fail_rate <- define_fail_rate(
duration = c(3, 100),
fail_rate = log(2) / c(9, 18),
dropout_rate = .001,
hr = c(1, .55)
)
total_duration <- 30Since there is a single stratum, we set strata to the
default:
strata <- tibble::tibble(stratum = "All", p = 1)Computing average hazard ratio
We compute an average hazard ratio using the
gsDesign2::ahr() (average hazard ratio) routine. We will
modify enrollment rates proportionately below when the sample size is
computed. This result is for the given enrollment rates which will be
adjusted in our next step. However, since they will be adjusted
proportionately with relative enrollment timing not changing, the
average hazard ratio will not change. Approximations of statistical
information under the null (info0) and alternate
(info) hypotheses are provided here. Recall that the
parameterization here is in terms of \(\log(HR)\), and, thus the information is
intended to approximate 1 over the variance for the Cox regression
coefficient for treatment effect; this will be checked with simulation
later.
avehr <- ahr(
enroll_rate = enroll_rate,
fail_rate = fail_rate,
total_duration = as.numeric(total_duration)
)
avehr |> gt()| time | ahr | n | event | info | info0 |
|---|---|---|---|---|---|
| 30 | 0.691405 | 108 | 58.13107 | 14.10216 | 14.53277 |
This result can be explained by the number of events observed before and after the first 3 months of treatment in each treatment group.
xx <- pw_info(
enroll_rate = enroll_rate,
fail_rate = fail_rate,
total_duration = as.numeric(total_duration)
)
xx |> gt()| time | stratum | t | hr | n | event | info | info0 |
|---|---|---|---|---|---|---|---|
| 30 | All | 0 | 1.00 | 12 | 22.24824 | 5.562060 | 5.562060 |
| 30 | All | 3 | 0.55 | 96 | 35.88283 | 8.540105 | 8.970708 |
Now we can replicate the geometric average hazard ratio (AHR)
computed using the ahr() routine above. We compute the
logarithm of each HR above and computed a weighted average weighting by
the expected number of events under each hazard ratio. Exponentiating
the resulting weighted average gives the geometric mean hazard ratio,
which we label as AHR.
| AHR |
|---|
| 0.691405 |
Deriving the design
With this average hazard ratio, we use the call for
gsDesign::nEvents() which uses the Schoenfeld (1981) approximation to derive a
targeted number of events. All you need for this is the average hazard
ratio from above, the randomization ratio (experimental/control), Type I
error and Type II error (1 - power).
target_event <- gsDesign::nEvents(
hr = avehr$ahr, # average hazard ratio computed above
ratio = 1, # randomization ratio
alpha = .025, # 1-sided Type I error
beta = .1 # Type II error (1-power)
)
target_event <- ceiling(target_event)
target_event
#> [1] 309We also compute proportionately increase the enrollment rates to achieve this targeted number of events; we round up the number of events required to the next higher integer.
# Update enroll_rate to obtain targeted events
enroll_rate$rate <- ceiling(target_event) / avehr$event * enroll_rate$rate
avehr <- ahr(
enroll_rate = enroll_rate,
fail_rate = fail_rate,
total_duration = as.numeric(total_duration)
)
avehr |> gt()| time | ahr | n | event | info | info0 |
|---|---|---|---|---|---|
| 30 | 0.691405 | 574.082 | 309 | 74.9611 | 77.25 |
We also compute sample size, rounding up to the nearest even integer.
Average hazard ratio and expected event accumulation over time
We examine the average hazard ratio as a function of trial duration with the modified enrollment required to power the trial. We also plot expected event accrual over time; although the graphs go through 40 months, recall that the targeted trial duration is 30 months. A key design consideration is selecting trial duration based on things like the degree of ahr improvement over time versus the urgency of completing the trial as quickly as possible, noting that the required sample size will decrease with longer follow-up.
avehrtbl <- ahr(
enroll_rate = enroll_rate,
fail_rate = fail_rate,
total_duration = 1:(total_duration + 10)
)
ggplot(avehrtbl, aes(x = time, y = ahr)) +
geom_line() +
ylab("Average HR") +
ggtitle("Average HR as a function of study duration")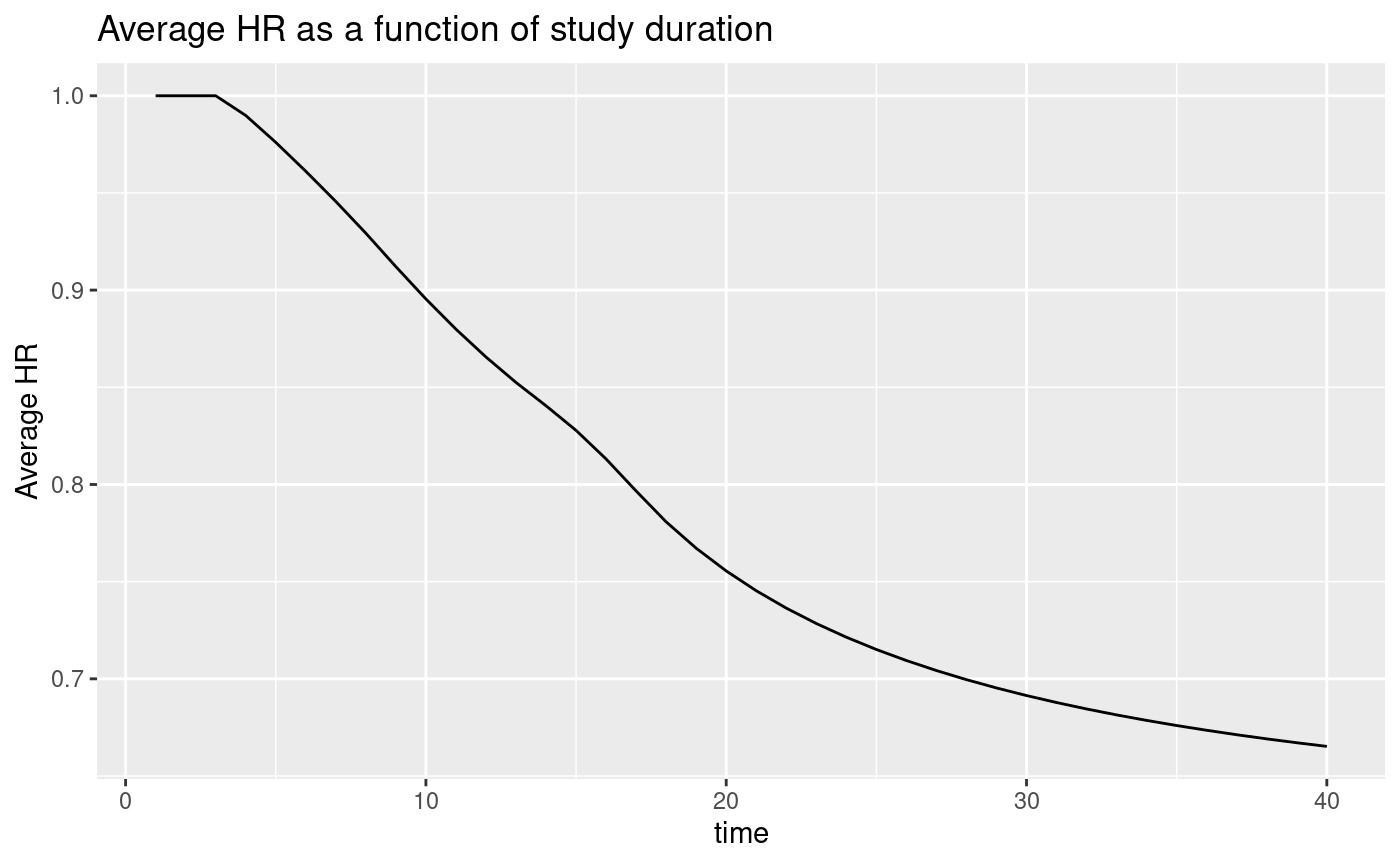
ggplot(avehrtbl, aes(x = time, y = event)) +
geom_line() +
ylab("Expected events") +
ggtitle("Expected event accumulation as a function of study duration")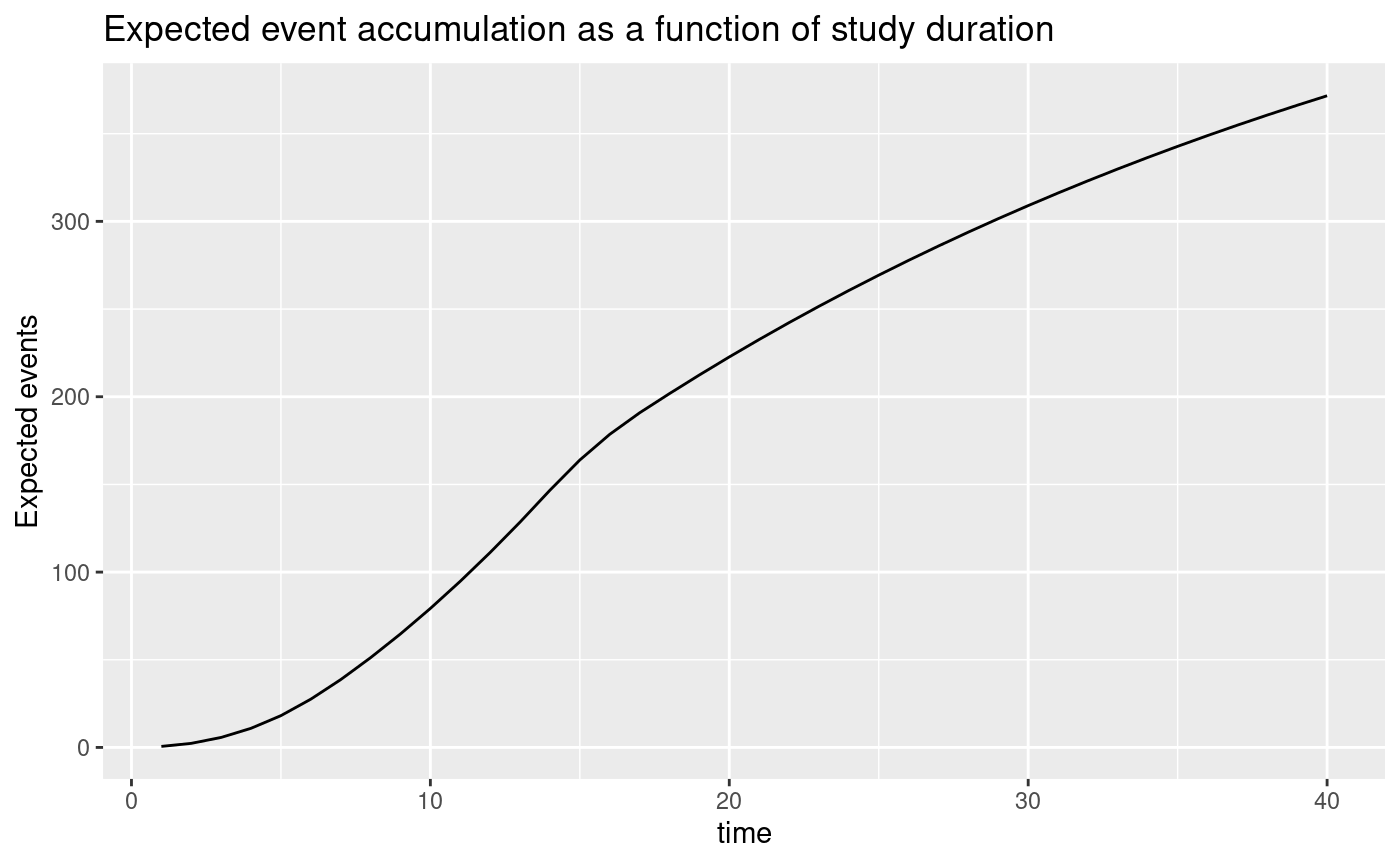
Simulation to verify power
We use function simtrial::sim_fixed_n() to simplify
setting up and executing a simulation to evaluate the sample size
derivation above. Arguments for simtrial::sim_fixed_n() are
slightly different than the set-up that was used for the
gsDesign2::ahr() function used above. Thus, there is some
reformatting of input parameters involved. One difference from the
gsDesign2::ahr() parameterization in
simtrial::sim_fixed_n() is that block is
provided to specify fixed block randomization as opposed to
ratio for gsDesign2::ahr().
# Do simulations
# Cut at targeted study duration
results1 <- simtrial::sim_fixed_n(
n_sim = nsim,
block = block,
sample_size = sample_size,
stratum = strata,
enroll_rate = enroll_rate,
fail_rate = fail_rate,
total_duration = total_duration,
target_event = ceiling(target_event),
timing_type = 1:5
)The following summarizes outcomes by the data cutoff chosen. Regardless of cutoff chosen, we see that the power approximates the targeted 90% quite well. The statistical information computed in the simulation is computed as one over the simulation variance of the Cox regression coefficient for treatment (i.e., the log hazard ratio).
results1$Positive <- results1$z <= qnorm(.025)
results1 |>
group_by(cut) |>
summarise(
Simulations = n(), Power = mean(Positive), sdDur = sd(duration), Duration = mean(duration),
sdEvents = sd(event), Events = mean(event),
HR = exp(mean(ln_hr)), sdlnhr = sd(ln_hr), info = 1 / sdlnhr^2
) |>
gt() |>
fmt_number(column = 2:9, decimals = 3)| cut | Simulations | Power | sdDur | Duration | sdEvents | Events | HR | sdlnhr | info |
|---|---|---|---|---|---|---|---|---|---|
| Max(min follow-up, event cut) | 1,000.000 | 0.000 | 0.993 | 30.594 | 7.283 | 314.294 | 0.691 | 0.120 | 69.23210 |
| Max(planned duration, event cut) | 1,000.000 | 0.000 | 0.937 | 30.571 | 7.137 | 314.103 | 0.691 | 0.120 | 69.13649 |
| Minimum follow-up | 1,000.000 | 0.000 | 0.489 | 30.027 | 11.939 | 310.040 | 0.693 | 0.121 | 68.69517 |
| Planned duration | 1,000.000 | 0.000 | 0.000 | 30.000 | 11.862 | 309.760 | 0.693 | 0.121 | 68.60037 |
| Targeted events | 1,000.000 | 0.000 | 1.601 | 29.870 | 0.000 | 309.000 | 0.694 | 0.122 | 67.01854 |
The column HR above is the exponentiated mean of the Cox
regression coefficients (geometric mean of HR). We see that the
HR estimate below matches the simulations above quite well.
The column info here is the estimated statistical
information under the alternate hypothesis, while info0 is
the estimate under the null hypothesis. The value of info0
is 1/4 of the expected events calculated below. In this case, the
information approximation under the alternate hypothesis appears
slightly small, meaning that the asymptotic approximation used will
overpower the trial. Nonetheless, the approximation for power appear
quite good as noted above.
avehr |> gt()| time | ahr | n | event | info | info0 |
|---|---|---|---|---|---|
| 30 | 0.691405 | 574.082 | 309 | 74.9611 | 77.25 |
Different proportional hazards by strata
Design scenario
We set up the design scenario parameter. We are limited here to
simultaneous enrollment of strata since the
simtrial::sim_fixed_n() routine uses
simtrial::sim_pw_surv() which is limited to this scenario.
We specify three strata:
- High risk: 1/3 of the population with median time-to-event of 6 months and a treatment effect hazard ratio of 1.2.
- Moderate risk: 1/2 of the population with median time-to-event of 9 months and a hazard ratio of 0.2.
- Low risk: 1/6 of the population that is essentially cured in both arms (median 100, HR = 1).
strata <- tibble::tibble(stratum = c("High", "Moderate", "Low"), p = c(1 / 3, 1 / 2, 1 / 6))
enroll_rate <- define_enroll_rate(
stratum = c(array("High", 4), array("Moderate", 4), array("Low", 4)),
duration = rep(c(2, 2, 2, 18), 3),
rate = c((1:4) / 3, (1:4) / 2, (1:4) / 6)
)
fail_rate <- define_fail_rate(
stratum = c("High", "Moderate", "Low"),
duration = 100,
fail_rate = log(2) / c(6, 9, 100),
dropout_rate = .001,
hr = c(1.2, 1 / 3, 1)
)
total_duration <- 36Computing average hazard ratio
Now we transform the enrollment rates to account for stratified population.
| time | ahr | n | event | info | info0 |
|---|---|---|---|---|---|
| 36 | 0.642733 | 84 | 53.41293 | 12.76869 | 13.35323 |
We examine the expected events by stratum.
| time | stratum | t | hr | n | event | info | info0 |
|---|---|---|---|---|---|---|---|
| 36 | High | 0 | 1.2000000 | 28 | 25.666089 | 6.4144810 | 6.4165222 |
| 36 | Low | 0 | 1.0000000 | 14 | 1.996737 | 0.4991842 | 0.4991842 |
| 36 | Moderate | 0 | 0.3333333 | 42 | 25.750105 | 5.8550281 | 6.4375262 |
Getting the average of log(HR) weighted by
Events and exponentiating, we get the overall
AHR just derived.
| lnhr | AHR |
|---|---|
| -0.4420259 | 0.642733 |
Deriving the design
We derive the sample size as before. We plan the sample size based on the average hazard ratio for the overall population and use that across strata. First, we derive the targeted events:
target_event <- gsDesign::nEvents(
hr = ahr2$ahr,
ratio = 1,
alpha = .025,
beta = .1
)
target_event <- ceiling(target_event)
target_event
#> [1] 216Next, we adapt enrollment rates proportionately so that the trial will be powered for the targeted failure rates and follow-up duration.
enroll_rate <- enroll_rate |> mutate(rate = target_event / ahr2$event * rate)
ahr(
enroll_rate = enroll_rate,
fail_rate = fail_rate,
total_duration = total_duration
) |> gt()| time | ahr | n | event | info | info0 |
|---|---|---|---|---|---|
| 36 | 0.642733 | 339.693 | 216 | 51.63614 | 54 |
The targeted sample size, rounding up to an even integer, is:
Average HR and expected event accumulation over time
Plotting the average hazard ratio as a function of study duration, we see that it improves considerably over the course of the study. We also plot expected event accumulation. As before, we plot for 10 months more than the planned study duration of 36 months to allow evaluation of event accumulation versus treatment effect for different trial durations.
avehrtbl <- ahr(
enroll_rate = enroll_rate,
fail_rate = fail_rate,
total_duration = 1:(total_duration + 10)
)
ggplot(avehrtbl, aes(x = time, y = ahr)) +
geom_line() +
ylab("Average HR") +
ggtitle("Average HR as a function of study duration")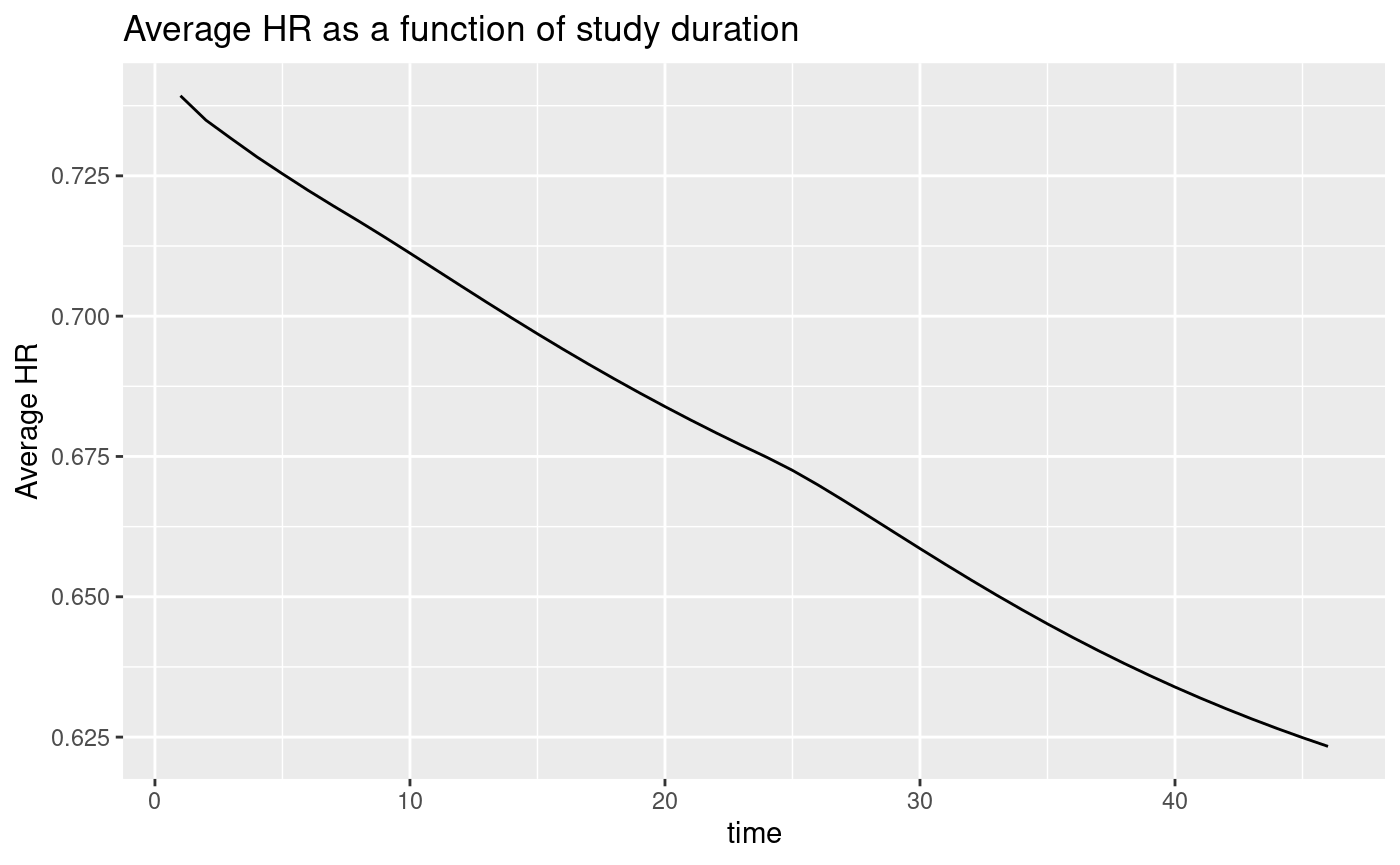
ggplot(avehrtbl, aes(x = time, y = event)) +
geom_line() +
ylab("Expected events") +
ggtitle("Expected event accumulation as a function of study duration")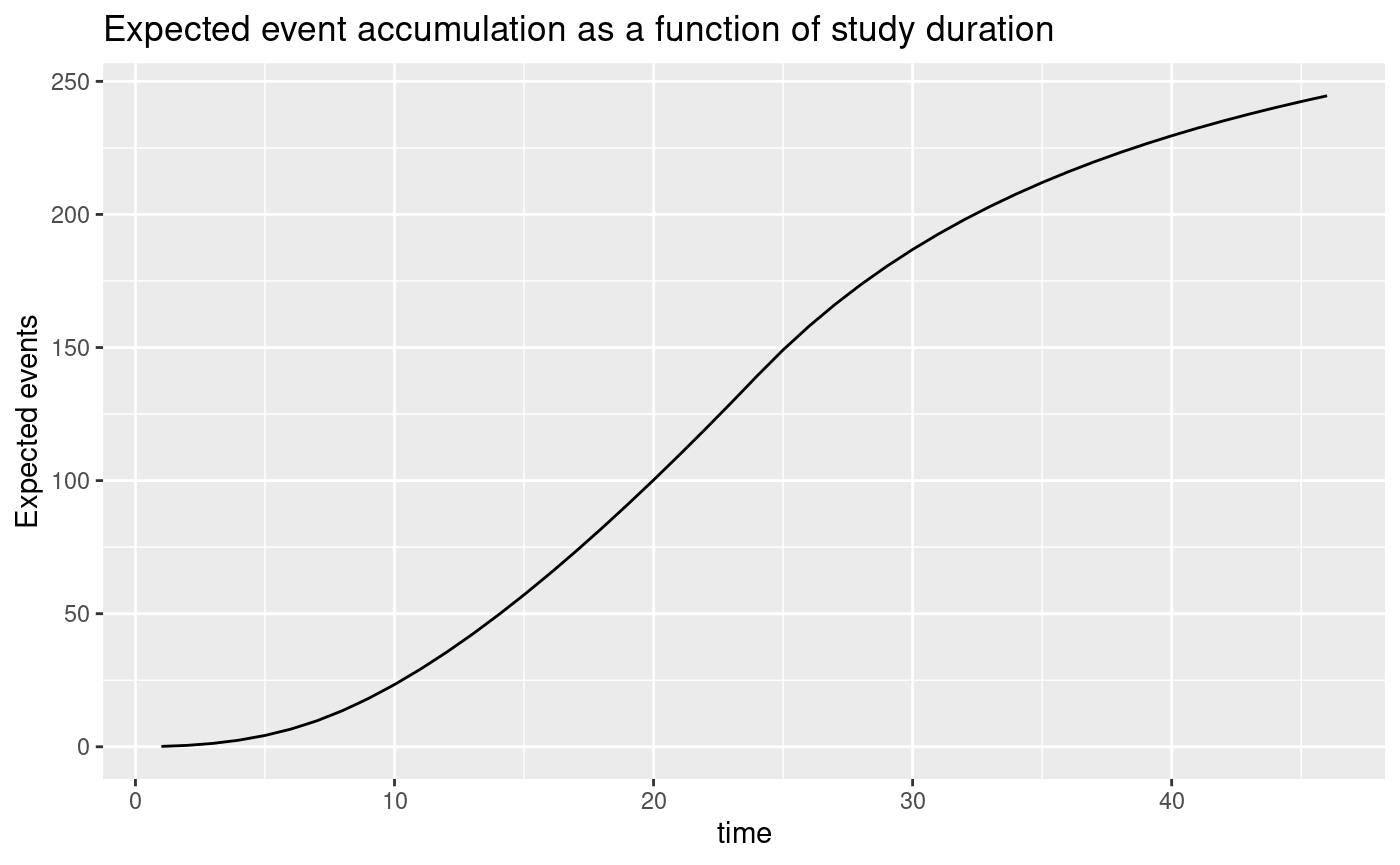
Simulation to verify power
We change the enrollment rates by stratum produced by
gsDesign::nSurv() to overall enrollment rates needed for
simtrial::sim_fixed_n().
er <- enroll_rate |>
group_by(stratum) |>
mutate(period = seq_len(n())) |>
group_by(period) |>
summarise(rate = sum(rate), duration = last(duration))
er |> gt()| period | rate | duration |
|---|---|---|
| 1 | 4.043965 | 2 |
| 2 | 8.087929 | 2 |
| 3 | 12.131894 | 2 |
| 4 | 16.175858 | 18 |
Now we simulate and summarize results. Once again, we see that the expected statistical information from the simulation is greater than what would be expected by the Schoenfeld approximation which is the expected events divided by 4.
results2 <- simtrial::sim_fixed_n(
n_sim = nsim,
block = block,
sample_size = sample_size,
stratum = strata,
enroll_rate = er,
fail_rate = fail_rate,
total_duration = as.numeric(total_duration),
target_event = as.numeric(target_event),
timing_type = 1:5
)
results2$Positive <- (pnorm(results2$z) <= .025)
results2 |>
group_by(cut) |>
summarize(
Simulations = n(), Power = mean(Positive), sdDur = sd(duration), Duration = mean(duration),
sdEvents = sd(event), Events = mean(event),
HR = exp(mean(ln_hr)), sdlnhr = sd(ln_hr), info = 1 / sdlnhr^2
) |>
gt() |>
fmt_number(column = 2:9, decimals = 3)| cut | Simulations | Power | sdDur | Duration | sdEvents | Events | HR | sdlnhr | info |
|---|---|---|---|---|---|---|---|---|---|
| Max(min follow-up, event cut) | 1,000.000 | 0.000 | 1.662 | 36.908 | 4.853 | 219.292 | 0.640 | 0.144 | 48.54706 |
| Max(planned duration, event cut) | 1,000.000 | 0.000 | 1.414 | 36.942 | 5.016 | 219.319 | 0.640 | 0.144 | 48.39566 |
| Minimum follow-up | 1,000.000 | 0.000 | 1.161 | 36.022 | 8.457 | 215.866 | 0.642 | 0.144 | 48.34920 |
| Planned duration | 1,000.000 | 0.000 | 0.000 | 36.000 | 8.795 | 215.559 | 0.642 | 0.144 | 48.39239 |
| Targeted events | 1,000.000 | 0.000 | 2.259 | 36.078 | 0.000 | 216.000 | 0.643 | 0.147 | 46.57092 |
Finally, compare the simulation results above to the asymptotic approximation below. The achieved power by simulation is just below the targeted 90%; noting that the simulation standard error is 0.006, the asymptotic approximation is quite good. Using the final cutoff that requires both the targeted events and minimum follow-up seems a reasonable convention to preserved targeted design power.
| time | ahr | n | event | info | info0 |
|---|---|---|---|---|---|
| 36 | 0.642733 | 339.693 | 216 | 51.63614 | 54 |