Basic tools for time-to-event trial simulation and testing
Keaven Anderson
Source:vignettes/routines.Rmd
routines.RmdOverview
This vignette demonstrates the lower-level routines in the simtrial package specifically related to trial generation and statistical testing.
The routines are as follows:
-
randomize_by_fixed_block()- fixed block randomization -
rpwexp_enroll()- random inter-arrival times with piecewise constant enrollment rates -
rpwexp()- piecewise exponential failure rate generation -
cut_data_by_date()- cut data for analysis at a specified calendar time -
cut_data_by_event()- cut data for analysis at a specified event count, including ties on the cutoff date -
get_cut_date_by_event()- find date at which an event count is reached -
counting_process()- pre-process survival data into a counting process format
Application of the above is demonstrated using higher-level routines
sim_pw_surv() and sim_fixed_n() to generate
simulations and weighted logrank analysis for a stratified design.
The intent has been to write these routines in the spirit of the tidyverse approach (alternately referred to as data wrangling, tidy data, R for Data Science, or split-apply-combine). The other objectives are to have an easily documentable and validated package that is easy to use and efficient as a broadly-useful tool for simulation of time-to-event clinical trials.
The package could be extended in many ways in the future, including:
- Other analyses not supported in the survival package or other
acceptably validated package
- Weighted logrank and weighted Kaplan-Meier analyses
- One-step, hazard ratio estimator (first-order approximation of PH)
- Randomization schemes other than stratified, fixed-block
- Poisson mixture or other survival distribution generation
Randomization
Fixed block randomization with an arbitrary block contents is performed as demonstrated below. In this case we have a block size of 5 with one string repeated twice in each block and three other strings appearing once each.
randomize_by_fixed_block(n = 10, block = c("A", "Dog", "Cat", "Cat"))
#> [1] "A" "Dog" "Cat" "Cat" "Dog" "Cat" "A" "Cat" "Cat" "Dog"More normally, with a default of blocks of size four:
randomize_by_fixed_block(n = 20)
#> [1] 0 0 1 1 1 0 0 1 0 1 0 1 1 0 0 1 1 1 0 0Enrollment
Piecewise constant enrollment can be randomly generated as follows. Note that duration is specifies interval durations for constant rates; the final rate is extended as long as needed to generate the specified number of observations.
rpwexp_enroll(
n = 20,
enroll_rate = data.frame(
duration = c(1, 2),
rate = c(2, 5)
)
)
#> [1] 0.4321713 1.1920483 1.3606775 1.4337998 1.9976912 2.2833587 2.3205687
#> [8] 2.3603258 2.4128677 2.5312003 2.5393496 2.8971532 3.0539522 3.2447750
#> [15] 3.6015153 3.6141447 3.7810793 4.2056592 4.4276540 4.5577338Time-to-event and time-to-dropout
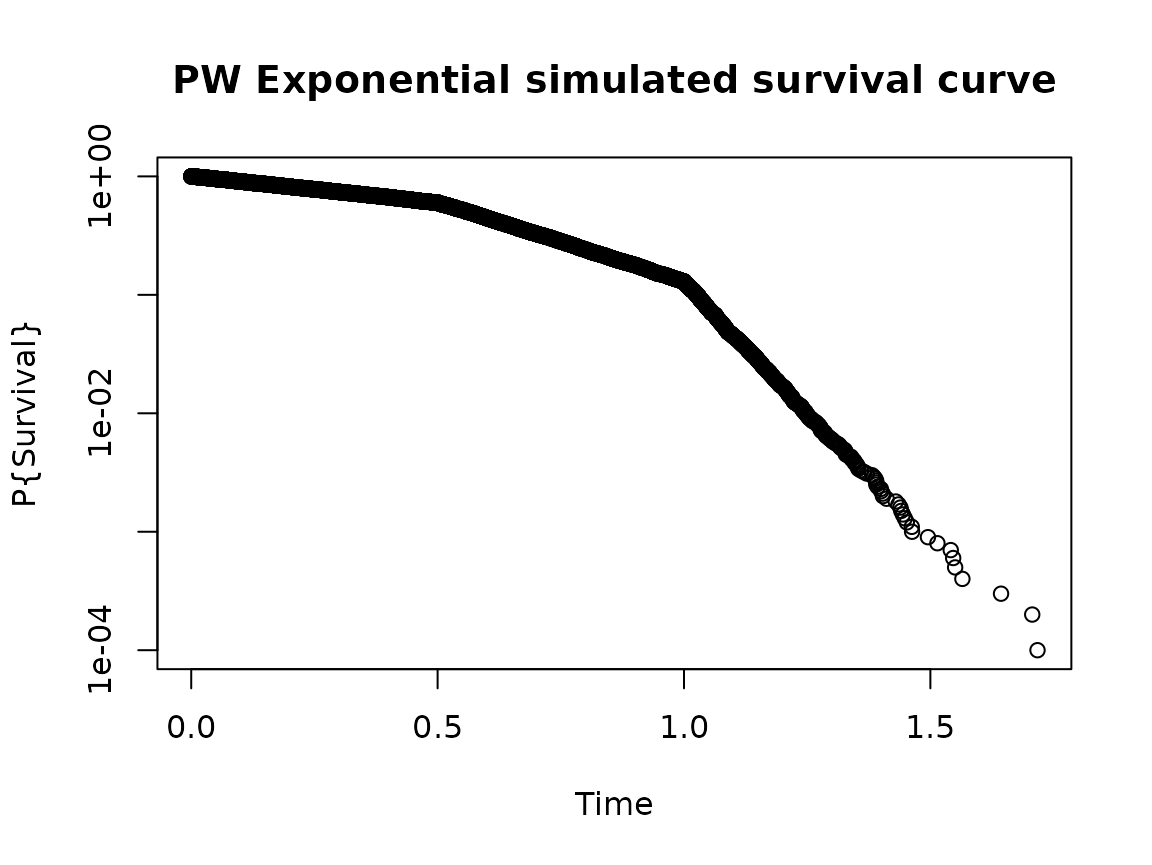
Time-to-event and time-to-dropout random number generation for observations is generated with piecewise exponential failure times. For a large number of observations, a log-plot of the time-to-failure
x <- rpwexp(
10000,
fail_rate = data.frame(
rate = c(1, 3, 10),
duration = c(.5, .5, 1)
)
)
plot(
sort(x),
(10000:1) / 10001,
log = "y",
main = "PW Exponential simulated survival curve",
xlab = "Time", ylab = "P{Survival}"
)
Generating a trial
Ideally, this might be done with a routine where generation of
randomization, and time-to-event data could be done in a modular fashion
plugged into a general trial generation routine. For now, stratified
randomization, piecewise constant enrollment, fixed block randomization
and piecewise exponential failure rates support a flexible set of trial
generation options for time-to-event endpoint trials. At present, follow
this format very carefully as little checking of input has been
developed to-date. The methods used here have all be demonstrated above,
but here they are combined in a single routine to generate a trial. Note
that in the generated output dataset, cte is the calendar
time of an event or dropout, whichever comes first, and
fail is an indicator that cte represents an
event time.
First we set up input variables to make the later call to
sim_pw_surv() more straightforward to read.
stratum <- data.frame(stratum = c("Negative", "Positive"), p = c(.5, .5))
block <- c(rep("control", 2), rep("experimental", 2))
enroll_rate <- data.frame(rate = c(3, 6, 9), duration = c(3, 2, 1))
fail_rate <- data.frame(
stratum = c(rep("Negative", 4), rep("Positive", 4)),
period = rep(1:2, 4),
treatment = rep(c(rep("control", 2), rep("experimental", 2)), 2),
duration = rep(c(3, 1), 4),
rate = log(2) / c(4, 9, 4.5, 10, 4, 9, 8, 18)
)
dropout_rate <- data.frame(
stratum = c(rep("Negative", 4), rep("Positive", 4)),
period = rep(1:2, 4),
treatment = rep(c(rep("control", 2), rep("experimental", 2)), 2),
duration = rep(c(3, 1), 4),
rate = rep(c(.001, .001), 4)
)
x <- sim_pw_surv(
n = 400,
stratum = stratum,
block = block,
enroll_rate = enroll_rate,
fail_rate = fail_rate,
dropout_rate = dropout_rate
)
head(x) |>
gt() |>
fmt_number(columns = c("enroll_time", "fail_time", "dropout_time", "cte"), decimals = 2)| stratum | enroll_time | treatment | fail_time | dropout_time | cte | fail |
|---|---|---|---|---|---|---|
| Negative | 0.02 | control | 0.56 | 27.24 | 0.58 | 1 |
| Negative | 0.69 | experimental | 3.32 | 1,893.19 | 4.01 | 1 |
| Negative | 0.80 | control | 1.16 | 820.85 | 1.96 | 1 |
| Positive | 1.07 | control | 5.68 | 112.63 | 6.75 | 1 |
| Negative | 1.13 | experimental | 64.98 | 2,670.46 | 66.11 | 1 |
| Negative | 1.14 | experimental | 8.19 | 531.96 | 9.34 | 1 |
Cutting data for analysis
There two ways to cut off data in the generated dataset
x from above. The first uses a calendar cutoff date. The
output only includes the time from randomization to event or dropout
(tte), and indicator that this represents and event
(event), the stratum in which the observation was generated
(stratum) and the treatment group assigned
(treatment). Observations enrolled after the input
cut_date are deleted and events and censoring from
x that are after the cut_date are censored at
the specified cut_date.
y <- cut_data_by_date(x, cut_date = 5)
head(y) |>
gt() |>
fmt_number(columns = "tte", decimals = 2)| tte | event | stratum | treatment |
|---|---|---|---|
| 0.56 | 1 | Negative | control |
| 3.32 | 1 | Negative | experimental |
| 1.16 | 1 | Negative | control |
| 3.93 | 0 | Positive | control |
| 3.87 | 0 | Negative | experimental |
| 3.86 | 0 | Negative | experimental |
For instance, if we wish to cut the entire dataset when 50 events are
observed in the Positive stratum we can use the
get_cut_date_by_event function as follows:
cut50Positive <- get_cut_date_by_event(filter(x, stratum == "Positive"), 50)
y50Positive <- cut_data_by_date(x, cut50Positive)
with(y50Positive, table(stratum, event))
#> event
#> stratum 0 1
#> Negative 41 53
#> Positive 46 50Perhaps the most common way to cut data is with an event count for
the overall population, which is done using the
cut_data_by_event function. Note that if there are tied
events at the date the cte the count is reached, all are
included. Also, if the count is never reached, all event times are
included in the cut - with no indication of an error.
y150 <- cut_data_by_event(x, 150)
table(y150$event, y150$treatment)
#>
#> control experimental
#> 0 44 54
#> 1 80 70Generating a counting process dataset
Once we have cut data for analysis, we can create a dataset that is
very simple to use for weighted logrank tests. A slightly more complex
version could be developed in the future to enable Kaplan-Meier-based
tests. We take the dataset y150 from above and process it
into this format. The counting process format is further discussed in
the next section where we compute a weighted logrank test.
ten150 <- counting_process(y150, arm = "experimental")
head(ten150) |>
gt() |>
fmt_number(columns = c("tte", "o_minus_e", "var_o_minus_e"), decimals = 2)| stratum | event_total | event_trt | tte | n_risk_total | n_risk_trt | s | o_minus_e | var_o_minus_e |
|---|---|---|---|---|---|---|---|---|
| Negative | 1 | 0 | 0.06 | 124 | 62 | 1.0000000 | −0.50 | 0.25 |
| Negative | 1 | 1 | 0.06 | 123 | 62 | 0.9919355 | 0.50 | 0.25 |
| Negative | 1 | 1 | 0.15 | 122 | 61 | 0.9838710 | 0.50 | 0.25 |
| Negative | 1 | 0 | 0.15 | 121 | 60 | 0.9758065 | −0.50 | 0.25 |
| Negative | 1 | 1 | 0.23 | 120 | 60 | 0.9677419 | 0.50 | 0.25 |
| Negative | 1 | 0 | 0.27 | 119 | 59 | 0.9596774 | −0.50 | 0.25 |
Logrank and weighted logrank testing
Now stratified logrank and stratified weighted logrank tests are
easily generated based on the counting process format. Each record in
the counting process dataset represents a tte at which one
or more events occurs; the results are stratum-specific. Included in the
observation is the number of such events overall (events)
and in the experimental treatment group (txevents), the
number at risk overall (atrisk) and in the experimental
treatment group (txatrisk) just before tte,
the combined treatment group Kaplan-Meier survival estimate
(left-continuous) at tte, the observed events in
experimental group minus the expected at tte based on an
assumption that all at risk observations are equally likely to have an
event at any time, and the variance for this quantity
(Var).
To generate a stratified logrank test and a corresponding one-sided p-value, we simply do the following:
z <- with(ten150, sum(o_minus_e) / sqrt(sum(var_o_minus_e)))
c(z, pnorm(z))
#> [1] -2.505355629 0.006116416A Fleming-Harrington \(\rho=1\), \(\gamma=2\) is nearly as simple. We again compute a z-statistic and its corresponding one-sided p-value.
xx <- mutate(ten150, w = s * (1 - s)^2)
z <- with(xx, sum(o_minus_e * w) / sum(sqrt(var_o_minus_e * w^2)))
c(z, pnorm(z))
#> [1] -0.1970797 0.4218826For Fleming-Harrington tests, a routine has been built to do these tests for you:
fh00 <- y150 |> wlr(weight = fh(rho = 0, gamma = 0))
fh01 <- y150 |> wlr(weight = fh(rho = 0, gamma = 1))
fh10 <- y150 |> wlr(weight = fh(rho = 1, gamma = 0))
fh11 <- y150 |> wlr(weight = fh(rho = 1, gamma = 1))
temp_tbl <- fh00 |>
unlist() |>
as.data.frame() |>
cbind(fh01 |> unlist() |> as.data.frame()) |>
cbind(fh10 |> unlist() |> as.data.frame()) |>
cbind(fh11 |> unlist() |> as.data.frame())
colnames(temp_tbl) <- c("Test 1", "Test 2", "Test 3", "Test 4")
temp_tbl
#> Test 1 Test 2 Test 3
#> method WLR WLR WLR
#> parameter FH(rho=0, gamma=0) FH(rho=0, gamma=1) FH(rho=1, gamma=0)
#> estimate -14.9849475025986 -4.58833802802725 -10.3966094745713
#> se 5.98116583796613 2.21990881849575 4.28272384915455
#> z 2.50535562941256 2.06690382496719 2.42756942561769
#> info 37.0469798657718 5.42019004111222 18.2768366472186
#> info0 37.25 5.44366046093289 18.6227889331453
#> Test 4
#> method WLR
#> parameter FH(rho=1, gamma=1)
#> estimate -2.69994556253347
#> se 1.13659961009608
#> z 2.37545881465262
#> info 1.36992936361306
#> info0 1.37044207369963If we wanted to take the minimum of these for a MaxCombo test, we
would first use fh_weight() to compute a correlation matrix
for the above z-statistics as follows. Note that the ordering of
rho_gamma and g in the argument list is
opposite of the above. The correlation matrix for the
z-values is now in V1-V4. We can
compute a p-value for the MaxCombo as follows using
mvtnorm::pmvnorm(). Note the arguments for
GenzBretz() which are more stringent than the defaults; we
have also used these more stringent parameters in the example in the
help file.
Simplification for 2-arm trials
The sim_fixed_n() routine combines much of the above to
go straight to generating tests for individual trials so that cutting
data and analyzing do not need to be done separately. Here the argument
structure is meant to be simpler than for
sim_pw_surv().
stratum <- data.frame(stratum = "All", p = 1)
enroll_rate <- data.frame(
duration = c(2, 2, 10),
rate = c(3, 6, 9)
)
fail_rate <- data.frame(
stratum = "All",
duration = c(3, 100),
fail_rate = log(2) / c(9, 18),
hr = c(0.9, 0.6),
dropout_rate = rep(0.001, 2)
)
block <- rep(c("experimental", "control"), 2)
rho_gamma <- data.frame(rho = 0, gamma = 0)Now we simulate a trial 2 times and cut data for analysis based on
timing_type = 1:5 which translates to:
- the planned study duration,
- targeted event count is achieved,
- planned minimum follow-up after enrollment is complete,
- the maximum of 1 and 2,
- the maximum of 2 and 3.
sim_fixed_n(
n_sim = 2, # Number of simulations
sample_size = 500, # Trial sample size
target_event = 350, # Targeted events at analysis
stratum = stratum, # Study stratum
enroll_rate = enroll_rate, # Enrollment rates
fail_rate = fail_rate, # Failure rates
total_duration = 30, # Planned trial duration
block = block, # Block for treatment
timing_type = 1:5, # Use all possible data cutoff methods
rho_gamma = rho_gamma # FH test(s) to use; in this case, logrank
) |>
gt() |>
fmt_number(columns = c("ln_hr", "z", "duration"))
#> Backend uses sequential processing.| method | parameter | estimate | se | z | event | ln_hr | cut | duration | sim |
|---|---|---|---|---|---|---|---|---|---|
| WLR | FH(rho=0, gamma=0) | -2.993631 | 5.496021 | 0.54 | 121 | −0.10 | Planned duration | 30.00 | 1 |
| WLR | FH(rho=0, gamma=0) | -34.168255 | 9.280556 | 3.68 | 350 | −0.40 | Targeted events | 64.89 | 1 |
| WLR | FH(rho=0, gamma=0) | -38.109119 | 9.562882 | 3.99 | 375 | −0.41 | Minimum follow-up | 71.75 | 1 |
| WLR | FH(rho=0, gamma=0) | -34.168255 | 9.280556 | 3.68 | 350 | −0.40 | Max(planned duration, event cut) | 64.89 | 1 |
| WLR | FH(rho=0, gamma=0) | -38.109119 | 9.562882 | 3.99 | 375 | −0.41 | Max(min follow-up, event cut) | 71.75 | 1 |
| WLR | FH(rho=0, gamma=0) | -17.318876 | 4.922279 | 3.52 | 99 | −0.73 | Planned duration | 30.00 | 2 |
| WLR | FH(rho=0, gamma=0) | -37.749178 | 9.190180 | 4.11 | 350 | −0.44 | Targeted events | 65.91 | 2 |
| WLR | FH(rho=0, gamma=0) | -38.404129 | 9.452228 | 4.06 | 371 | −0.42 | Minimum follow-up | 73.50 | 2 |
| WLR | FH(rho=0, gamma=0) | -37.749178 | 9.190180 | 4.11 | 350 | −0.44 | Max(planned duration, event cut) | 65.91 | 2 |
| WLR | FH(rho=0, gamma=0) | -38.404129 | 9.452228 | 4.06 | 371 | −0.42 | Max(min follow-up, event cut) | 73.50 | 2 |
If you look carefully, you should be asking why the cutoff with the
planned number of events is so different than the other data cutoff
methods. To explain, we note that generally you will want
sample_size above to match the enrollment specified in
enroll_rate:
enroll_rate |> summarize(
"Targeted enrollment based on input enrollment rates" = sum(duration * rate)
)
#> Targeted enrollment based on input enrollment rates
#> 1 108The targeted enrollment takes, on average, 30 months longer than the
sum of the enrollment durations in enroll_rate (14 months)
at the input enrollment rates. To achieve the input
sample_size of 500, the final enrollment rate is assumed to
be steady state and extends in each simulation until the targeted
enrollment is achieved. The planned duration of the trial is taken as 30
months as specified in total_duration. The targeted minimum
follow-up is
total_duration <- 30 # From above
total_duration - sum(enroll_rate$duration)
#> [1] 16It is thus, implicit that the last subject was enrolled 16 months
prior to the duration given for the cutoff with “Minimum follow-up”
cutoff in the simulations above. The planned duration cutoff is given in
the total_duration argument which results in a much earlier
cutoff.