Quickstart guide
Zifang Guo, Keaven Anderson, Jing Zhao, Linda Z. Sun
Source:vignettes/wpgsd.Rmd
wpgsd.Rmd
library(wpgsd)
library(gsDesign)
library(gMCPLite)
library(haven)
library(dplyr)
library(tidyr)
library(reshape2)
library(gt)Background
The weighted parametric group sequential design (WPGSD) (Anderson et al. (2022)) approach allows one to take advantage of the known correlation structure in constructing efficacy bounds to control family-wise error rate (FWER) for a group sequential design. Here correlation may be due to common observations in nested populations, due to common observations in overlapping populations, or due to common observations in the control arm. This document illustrates the use of the R package wpgsd to implement this approach.
Methods and Examples
Closed Testing and Parametric Tests
We aim to control the familywise error rate (FWER) at level . Let . The intersection hypothesis assumes the null hypothesis for all individual hypotheses with . Closed testing principle is as follows: if for all sets with , can be rejected at level , then can be rejected. Weighted parametric tests can be used for this: Bretz et al. (2011), Xi et al. (2017) for fixed designs or Maurer and Bretz (2013) for group sequential.
Consonance
A closed procedure is called consonant if the rejection of the
complete intersection null hypothesis
further implies
that at least one elementary hypothesis
,
is rejected.
Consonance is a desirable property leading to short-cut procedures that
give the same rejection decisions as the original closed procedure but
with fewer operations. For WPGSD, consonance does not always hold and in
general the closed-testing procedure is required.
Group Sequential Design Notation and Assumptions
- A set of hypotheses for .
- group sequential analyses,
- Single endpoint
- Not required, and can be generalized
- Assume tests , , where a large is used to reject
Correlation Structure
-
Notation
- Events for individual hypothesis , at analysis denoted by .
- Assume the same endpoint for all hypotheses (can be relaxed)
- For binary or continuous outcomes represents sample size
- is standardized normal test for treatment effect for individual hypothesis at analysis
- Denote as the number of observations (or events) included in both and , , .
-
Key result
$$\hbox{Corr}(Z_{ik}, Z_{i^\prime k^\prime }) = \frac{n_{i\wedge i^\prime ,k\wedge k^\prime }}{\sqrt{n_{ik}n_{i^\prime k^\prime }}}$$
Proof builds on standard group sequential theory (Chen et al. (2021))
Example 1: Overlapping Populations, Two Analyses
Following illustrates the first example, which has overlapping populations (e.g. due to biomarker) and is also example 1 in Anderson et al. (2022).
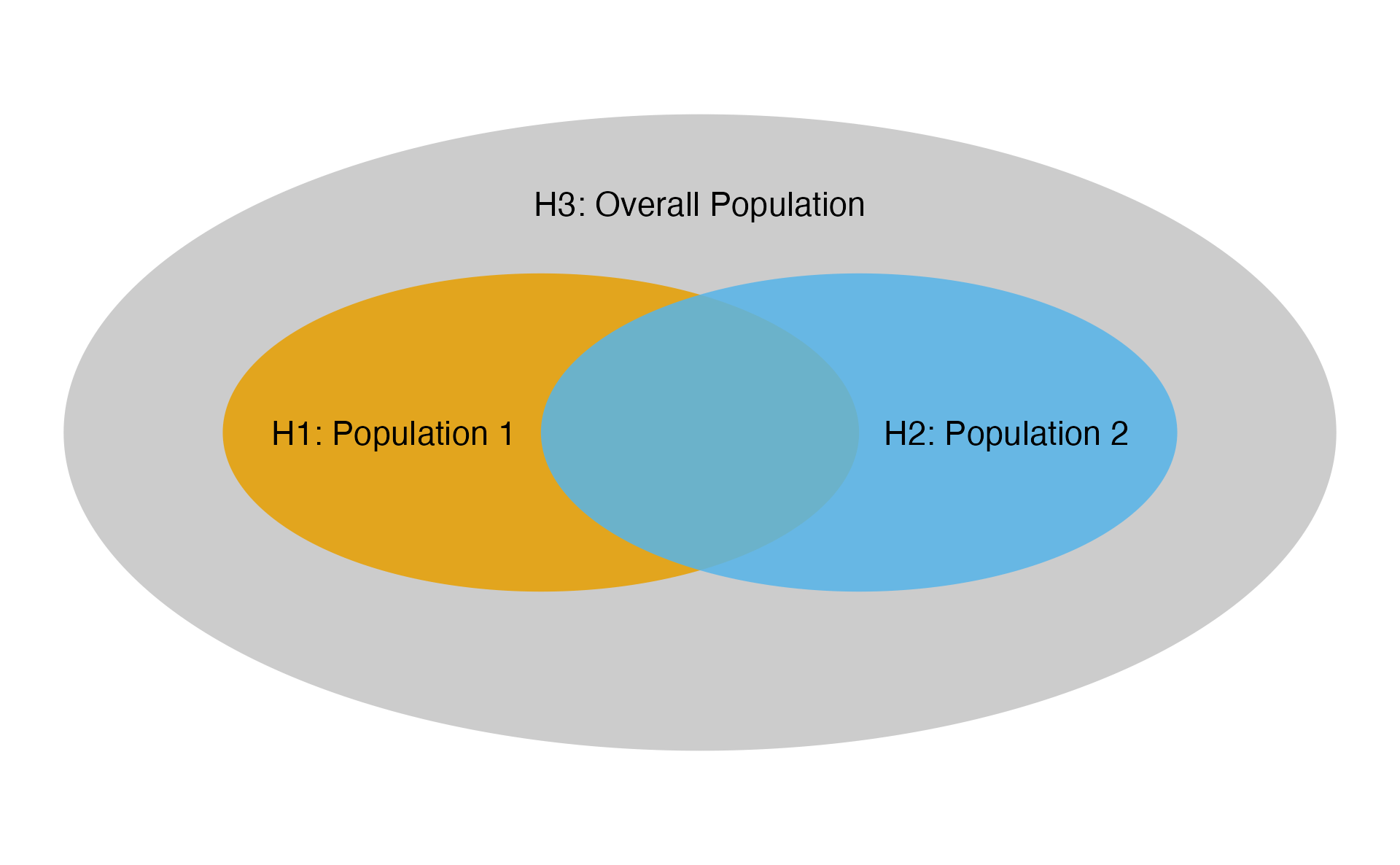
Ex1: Populations
The multiplicity strategy is defined as follows.
# Transition matrix
m <- matrix(c(
0, 0, 1,
0, 0, 1,
0.5, 0.5, 0
), nrow = 3, byrow = TRUE)
# Weight matrix
w <- c(0.3, 0.3, 0.4)
# Multiplicity graph
cbPalette <- c("#999999", "#E69F00", "#56B4E9")
nameHypotheses <- c(
"H1: Population 1",
"H2: Population 2",
"H3: Overall Population"
)
hplot <- hGraph(3,
alphaHypotheses = w,
m = m,
nameHypotheses = nameHypotheses,
trhw = .2, trhh = .1,
digits = 5, trdigits = 3, size = 5, halfWid = 1,
halfHgt = 0.5, offset = 0.2, trprop = 0.4,
fill = as.factor(c(2, 3, 1)),
palette = cbPalette,
wchar = "w"
)
hplot
The event count of each hypothesis at each analysis is shown below.
| Population | Number of Events at IA | Number of Events at FA |
|---|---|---|
| Population 1 | 100 | 200 |
| Population 2 | 110 | 220 |
| Population 1 2 | 80 | 160 |
| Overall Population | 225 | 450 |
The correlation matrix among test statistics is as follows.
| 1,1 | 2,1 | 3,1 | 1,2 | 2,2 | 3,2 | |
|---|---|---|---|---|---|---|
| 1,1 | 1 | |||||
| 2,1 | 0.76 | 1 | ||||
| 3,1 | 0.67 | 0.70 | 1 | |||
| 1,2 | 0.71 | 0.54 | 0.47 | 1 | ||
| 2,2 | 0.54 | 0.71 | 0.49 | 0.76 | 1 | |
| 3,2 | 0.47 | 0.49 | 0.71 | 0.67 | 0.70 | 1 |
Example 2: Common Control, Two Analyses
Following illustrates the second example in which correlation comes from common control arm. This is also example 2 in Anderson et al. (2022).

| Treatment Arm | Number of Events at IA | Number of Events at FA |
|---|---|---|
| Experimental 1 | 70 | 135 |
| Experimental 2 | 75 | 150 |
| Experimental 3 | 80 | 165 |
| Control | 85 | 170 |
| 1,1 | 2,1 | 3,1 | 1,2 | 2,2 | 3,2 | |
|---|---|---|---|---|---|---|
| 1,1 | 1 | |||||
| 2,1 | 0.54 | 1 | ||||
| 3,1 | 0.53 | 0.52 | 1 | |||
| 1,2 | 0.71 | 0.38 | 0.38 | 1 | ||
| 2,2 | 0.38 | 0.71 | 0.37 | 0.54 | 1 | |
| 3,2 | 0.37 | 0.37 | 0.70 | 0.53 | 0.52 | 1 |
Hypotheses Set
These 2 examples each has 7 intersection hypotheses and the corresponding weighting strategies are illustrated below.
| 0.3 | 0.3 | 0.4 | |
| 0.5 | 0.5 | - | |
| 0.3 | - | 0.7 | |
| - | 0.3 | 0.7 | |
| 1 | - | - | |
| - | 1 | - | |
| - | - | 1 |
| 1/3 | 1/3 | 1/3 | |
| 1/2 | 1/2 | - | |
| 1/2 | - | 1/2 | |
| - | 1/2 | 1/2 | |
| 1 | - | - | |
| - | 1 | - | |
| - | - | 1 |
Spending: 3 approaches
The WPGSD approach uses all known correlations between tests in the study. This relaxes bounds and allows increased power or smaller sample size. Three spending approaches have been proposed:
Fixed spending (Fleming-Harrington-O’Brien (FHO) approach). Specify for all , where is the total alpha for intersection hypothesis according to the graphical approach.
-spending approach 1. We choose a spending function family and set for for all intersection hypotheses .
-spending approach 2. For each elementary hypothesis (), specify the -spending function family where is the level for the hypothesis and determines how much to spend up to analysis for hypothesis when level is allocated to the hypothesis. Then .
Bounds Computation: Parametric Test, Fixed Design (For Example, Two Populations, One Analysis)
Assume () bivariate normal with known correlation
Find -inflation factor such that
Basic algorithm code in Bretz et al. (2011)
Bounds Computation: WPGSD - Fixed spending and spending approach 1
Assume for that bounds , have already been set and remain unchanged.
-
At analysis , compute the correlation matrix of , , .
i Initialize .
ii Set , .
iii Compute type I error rate up to analysis
iv Update using root-finding with steps ii - iii until the type I error rate through analysis is controlled at for . That is,
v Set from the previous step. The corresponding nominal -value boundary is .
Note: interim bound does not depend on future analyses. Solution only requires root finding for a single at a time, . Requires multivariate normal computation from mvtnorm R package Genz et al. (2020).
Bounds Computation: WPGSD - spending approach 2
Assume for that bounds , have already been set and remain unchanged.
-
At analysis , compute the correlation matrix of , , .
i Determine what the nominal -value boundary would be for each elementary hypothesis in for a weighted Bonferroni test in a group sequential design as described in Maurer and Bretz (2013). Let these nominal -value boundaries be .
ii Choose an inflation factor and set
iii Update until this type I error rate up to analysis is controlled at for . That is,
iv After the appropriate has been derived, the nominal -value boundaries are , and is computed as in step ii, we set .
Note: interim bound does not depend on future analyses. Solution only requires root finding for a single at a time, . Requires multivariate normal computation from the mvtnorm R package Genz et al. (2020).
Implementation of Example 1 with Overlapping Populations
We first define the transition matrix and weights as shown above in Section 2.5. Next we set up the event count table as follows:
- Analysis: Analysis number (1 for interim, 2 for final).
- Event: Event counts.
- H1, H2: Hypotheses intersected.
- (1, 1) represents counts for hypothesis 1
- (1, 2) for counts for the intersection of hypotheses 1 and 2
event <- tribble(
~H1, ~H2, ~Analysis, ~Event,
1, 1, 1, 100,
2, 2, 1, 110,
3, 3, 1, 225,
1, 2, 1, 80,
1, 3, 1, 100,
2, 3, 1, 110,
1, 1, 2, 200,
2, 2, 2, 220,
3, 3, 2, 450,
1, 2, 2, 160,
1, 3, 2, 200,
2, 3, 2, 220
)
event %>%
gt() %>%
tab_header(title = "Event Count")| Event Count | |||
| H1 | H2 | Analysis | Event |
|---|---|---|---|
| 1 | 1 | 1 | 100 |
| 2 | 2 | 1 | 110 |
| 3 | 3 | 1 | 225 |
| 1 | 2 | 1 | 80 |
| 1 | 3 | 1 | 100 |
| 2 | 3 | 1 | 110 |
| 1 | 1 | 2 | 200 |
| 2 | 2 | 2 | 220 |
| 3 | 3 | 2 | 450 |
| 1 | 2 | 2 | 160 |
| 1 | 3 | 2 | 200 |
| 2 | 3 | 2 | 220 |
# Alternatively, one can manually enter paths for analysis datasets,
# example below uses an example dataset assuming currently we are at IA1.
paths <- system.file("extdata/", package = "wpgsd")
### Generate event count table from ADSL and ADTTE datasets
# Selection criteria for each hypothesis
h_select <- tribble(
~Hypothesis, ~Crit,
1, "PARAMCD=='OS' & TRT01P %in% c('Xanomeline High Dose', 'Placebo')",
2, "PARAMCD=='OS' & TRT01P %in% c('Xanomeline Low Dose', 'Placebo')"
)
event2 <- generate_event_table(paths, h_select,
adsl_name = "adsl", adtte_name = "adtte",
key_var = "USUBJID", cnsr_var = "CNSR"
)$event
event2 %>%
gt() %>%
tab_header(title = "Event Count - Computed from SAS Datasets Example")| Event Count - Computed from SAS Datasets Example | |||
| H1 | H2 | Analysis | Event |
|---|---|---|---|
| 1 | 1 | 1 | 66 |
| 2 | 2 | 1 | 59 |
| 1 | 2 | 1 | 45 |
Then we compute correlation matrix using the event count table and
generate_corr(). We see that the correlations not accounted
for by the Bonferroni approach are substantial and, thus, might expect a
non-trivial impact on bounds for hypothesis tests.
## Generate correlation from events
corr <- generate_corr(event)
corr %>%
as_tibble() %>%
gt() %>%
fmt_number(columns = everything(), decimals = 2) %>%
tab_header(title = "Correlation Matrix")| Correlation Matrix | |||||
| H1_A1 | H2_A1 | H3_A1 | H1_A2 | H2_A2 | H3_A2 |
|---|---|---|---|---|---|
| 1.00 | 0.76 | 0.67 | 0.71 | 0.54 | 0.47 |
| 0.76 | 1.00 | 0.70 | 0.54 | 0.71 | 0.49 |
| 0.67 | 0.70 | 1.00 | 0.47 | 0.49 | 0.71 |
| 0.71 | 0.54 | 0.47 | 1.00 | 0.76 | 0.67 |
| 0.54 | 0.71 | 0.49 | 0.76 | 1.00 | 0.70 |
| 0.47 | 0.49 | 0.71 | 0.67 | 0.70 | 1.00 |
Bonferroni and WPGSD bounds can then be computed via
generate_bounds(). In this example, we useHSD(-4) as
-spending
for all hypotheses. Of note, generate_bounds() input
type specifies boundary type.
- 0 = Bonferroni. Separate alpha spending for each hypotheses.
- 1 = Fixed alpha spending for all hypotheses. Method 3a in the manuscript.
- 2 = Overall alpha spending for all hypotheses. Method 3b in the manuscript.
- 3 = Separate alpha spending for each hypotheses. Method 3c in the manuscript.
Compute Bonferroni bounds.
# Bonferroni bounds
bound_Bonf <- generate_bounds(
type = 0, k = 2, w = w, m = m,
corr = corr, alpha = 0.025,
sf = list(sfHSD, sfHSD, sfHSD),
sfparm = list(-4, -4, -4),
t = list(c(0.5, 1), c(0.5, 1), c(0.5, 1))
)
bound_Bonf %>%
gt() %>%
fmt_number(columns = 3:5, decimals = 4) %>%
tab_header(title = "Bonferroni bounds")| Bonferroni bounds | ||||
| Analysis | Hypotheses | H1 | H2 | H3 |
|---|---|---|---|---|
| 1 | H1 | 0.0030 | NA | NA |
| 1 | H1, H2 | 0.0015 | 0.0015 | NA |
| 1 | H1, H2, H3 | 0.0009 | 0.0009 | 0.0012 |
| 1 | H1, H3 | 0.0013 | NA | 0.0016 |
| 1 | H2 | NA | 0.0030 | NA |
| 1 | H2, H3 | NA | 0.0013 | 0.0016 |
| 1 | H3 | NA | NA | 0.0030 |
| 2 | H1 | 0.0238 | NA | NA |
| 2 | H1, H2 | 0.0118 | 0.0118 | NA |
| 2 | H1, H2, H3 | 0.0070 | 0.0070 | 0.0094 |
| 2 | H1, H3 | 0.0106 | NA | 0.0130 |
| 2 | H2 | NA | 0.0238 | NA |
| 2 | H2, H3 | NA | 0.0106 | 0.0130 |
| 2 | H3 | NA | NA | 0.0238 |
Compute WPGSD Bounds using -spending approach 1 with HSD(-4) spending. Here spending time was defined as minimum of the 3 observed information fractions.
set.seed(1234)
# WPGSD bounds, spending approach 1
bound_WPGSD <- generate_bounds(
type = 2, k = 2, w = w, m = m,
corr = corr, alpha = 0.025,
sf = sfHSD,
sfparm = -4,
t = c(min(100 / 200, 110 / 220, 225 / 450), 1)
)
bound_WPGSD %>%
gt() %>%
fmt_number(columns = 3:5, decimals = 4) %>%
tab_header(title = "WPGSD bounds")| WPGSD bounds | ||||
| Analysis | Hypotheses | H1 | H2 | H3 |
|---|---|---|---|---|
| 1 | H1 | 0.0030 | NA | NA |
| 1 | H1, H2 | 0.0017 | 0.0017 | NA |
| 1 | H1, H2, H3 | 0.0011 | 0.0011 | 0.0014 |
| 1 | H1, H3 | 0.0014 | NA | 0.0018 |
| 1 | H2 | NA | 0.0030 | NA |
| 1 | H2, H3 | NA | 0.0015 | 0.0018 |
| 1 | H3 | NA | NA | 0.0030 |
| 2 | H1 | 0.0238 | NA | NA |
| 2 | H1, H2 | 0.0144 | 0.0144 | NA |
| 2 | H1, H2, H3 | 0.0092 | 0.0092 | 0.0123 |
| 2 | H1, H3 | 0.0122 | NA | 0.0149 |
| 2 | H2 | NA | 0.0238 | NA |
| 2 | H2, H3 | NA | 0.0124 | 0.0152 |
| 2 | H3 | NA | NA | 0.0238 |
Below shows the comparison between the Bonferroni and WPGSD bounds. Nominal level at final analysis by using the WPGSD method increased by up to 1.3× over those obtained via the Bonferroni approach.
| Bonferroni and WPGSD Bounds | ||||||||
| Analysis | Hypotheses | H1.B | H2.B | H3.B | H1.W | H2.W | H3.W | xi |
|---|---|---|---|---|---|---|---|---|
| 1 | H1, H2, H3 | 0.0009 | 0.0009 | 0.0012 | 0.0011 | 0.0011 | 0.0014 | 1.1770 |
| 1 | H1, H2 | 0.0015 | 0.0015 | NA | 0.0017 | 0.0017 | NA | 1.1363 |
| 1 | H1, H3 | 0.0013 | NA | 0.0016 | 0.0014 | NA | 0.0018 | 1.0810 |
| 1 | H2, H3 | NA | 0.0013 | 0.0016 | NA | 0.0015 | 0.0018 | 1.0962 |
| 1 | H1 | 0.0030 | NA | NA | 0.0030 | NA | NA | 1.0000 |
| 1 | H2 | NA | 0.0030 | NA | NA | 0.0030 | NA | 1.0000 |
| 1 | H3 | NA | NA | 0.0030 | NA | NA | 0.0030 | 1.0000 |
| 2 | H1, H2, H3 | 0.0070 | 0.0070 | 0.0094 | 0.0092 | 0.0092 | 0.0123 | 1.3092 |
| 2 | H1, H2 | 0.0118 | 0.0118 | NA | 0.0144 | 0.0144 | NA | 1.2250 |
| 2 | H1, H3 | 0.0106 | NA | 0.0130 | 0.0122 | NA | 0.0149 | 1.1532 |
| 2 | H2, H3 | NA | 0.0106 | 0.0130 | NA | 0.0124 | 0.0152 | 1.1735 |
| 2 | H1 | 0.0238 | NA | NA | 0.0238 | NA | NA | 1.0000 |
| 2 | H2 | NA | 0.0238 | NA | NA | 0.0238 | NA | 1.0000 |
| 2 | H3 | NA | NA | 0.0238 | NA | NA | 0.0238 | 1.0000 |
Closed testing procedure can then be performed using
closed_test().
## Observed p-values.
## The tibble must contain columns Analysis, H1, H2 etc for all hypotheses
p_obs <- tribble(
~Analysis, ~H1, ~H2, ~H3,
1, 0.01, 0.0004, 0.03,
2, 0.05, 0.002, 0.015
)
## Closed testing ##
test_result <- closed_test(bound_WPGSD, p_obs)
p_obs %>%
gt() %>%
fmt_number(columns = 2:4, decimals = 8, drop_trailing_zeros = TRUE) %>%
tab_header("Observed Nominal p-Values")| Observed Nominal p-Values | |||
| Analysis | H1 | H2 | H3 |
|---|---|---|---|
| 1 | 0.01 | 0.0004 | 0.03 |
| 2 | 0.05 | 0.002 | 0.015 |
test_result %>%
gt() %>%
tab_header(title = "Closed Testing Results")| Closed Testing Results | |||
| H1 | H2 | H3 | Analysis |
|---|---|---|---|
| Fail | Success | Fail | Analysis 1 |
| Fail | Success | Fail | Analysis 2 |
Implementation of Example 2 with Common Control
Similarly, codes below reproduce the result of Example 2 of Anderson et al. (2022), which uses spending method 3c specified in the paper.
set.seed(1234)
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Ex2 BH ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~#
# Transition matrix in Figure A2
m <- matrix(c(
0, 0.5, 0.5,
0.5, 0, 0.5,
0.5, 0.5, 0
), nrow = 3, byrow = TRUE)
# Initial weights
w <- c(1 / 3, 1 / 3, 1 / 3)
# Event count of intersection of paired hypotheses - Table 2
event <- tribble(
~H1, ~H2, ~Analysis, ~Event,
1, 1, 1, 155,
2, 2, 1, 160,
3, 3, 1, 165,
1, 2, 1, 85,
1, 3, 1, 85,
2, 3, 1, 85,
1, 1, 2, 305,
2, 2, 2, 320,
3, 3, 2, 335,
1, 2, 2, 170,
1, 3, 2, 170,
2, 3, 2, 170
)
event %>%
gt() %>%
tab_header(title = "Event Count")| Event Count | |||
| H1 | H2 | Analysis | Event |
|---|---|---|---|
| 1 | 1 | 1 | 155 |
| 2 | 2 | 1 | 160 |
| 3 | 3 | 1 | 165 |
| 1 | 2 | 1 | 85 |
| 1 | 3 | 1 | 85 |
| 2 | 3 | 1 | 85 |
| 1 | 1 | 2 | 305 |
| 2 | 2 | 2 | 320 |
| 3 | 3 | 2 | 335 |
| 1 | 2 | 2 | 170 |
| 1 | 3 | 2 | 170 |
| 2 | 3 | 2 | 170 |
# Generate correlation from events
corr <- generate_corr(event)
# Correlation matrix in Table 4
corr %>%
as_tibble() %>%
gt() %>%
fmt_number(columns = everything(), decimals = 2) %>%
tab_header(title = "Correlation Matrix")| Correlation Matrix | |||||
| H1_A1 | H2_A1 | H3_A1 | H1_A2 | H2_A2 | H3_A2 |
|---|---|---|---|---|---|
| 1.00 | 0.54 | 0.53 | 0.71 | 0.38 | 0.37 |
| 0.54 | 1.00 | 0.52 | 0.38 | 0.71 | 0.37 |
| 0.53 | 0.52 | 1.00 | 0.38 | 0.37 | 0.70 |
| 0.71 | 0.38 | 0.38 | 1.00 | 0.54 | 0.53 |
| 0.38 | 0.71 | 0.37 | 0.54 | 1.00 | 0.52 |
| 0.37 | 0.37 | 0.70 | 0.53 | 0.52 | 1.00 |
# WPGSD bounds, spending method 3c
bound_WPGSD <- generate_bounds(
type = 3, k = 2, w = w, m = m, corr = corr, alpha = 0.025,
sf = list(sfLDOF, sfLDOF, sfLDOF),
sfparm = list(0, 0, 0),
t = list(c(155 / 305, 1), c(160 / 320, 1), c(165 / 335, 1))
)
# Bonferroni bounds
bound_Bonf <- generate_bounds(
type = 0, k = 2, w = w, m = m, corr = corr, alpha = 0.025,
sf = list(sfLDOF, sfLDOF, sfLDOF),
sfparm = list(0, 0, 0),
t = list(c(155 / 305, 1), c(160 / 320, 1), c(165 / 335, 1))
)
bounds <- left_join(bound_Bonf, bound_WPGSD,
by = c("Hypotheses", "Analysis"),
suffix = c(".B", ".W")
)
# Reorder for output
bounds$order <- rep(c(5, 2, 1, 3, 6, 4, 7), 2)
bounds <- bounds %>%
arrange(Analysis, order) %>%
select(-order)
# Table A6
bounds %>%
gt() %>%
fmt_number(columns = 3:9, decimals = 4) %>%
tab_header(title = "Bonferroni and WPGSD Bounds")| Bonferroni and WPGSD Bounds | ||||||||
| Analysis | Hypotheses | H1.B | H2.B | H3.B | H1.W | H2.W | H3.W | xi |
|---|---|---|---|---|---|---|---|---|
| 1 | H1, H2, H3 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 1.0421 |
| 1 | H1, H2 | 0.0005 | 0.0004 | NA | 0.0005 | 0.0004 | NA | 1.0266 |
| 1 | H1, H3 | 0.0005 | NA | 0.0004 | 0.0005 | NA | 0.0004 | 1.0247 |
| 1 | H2, H3 | NA | 0.0004 | 0.0004 | NA | 0.0004 | 0.0004 | 1.0230 |
| 1 | H1 | 0.0017 | NA | NA | 0.0017 | NA | NA | 1.0000 |
| 1 | H2 | NA | 0.0015 | NA | NA | 0.0015 | NA | 1.0000 |
| 1 | H3 | NA | NA | 0.0014 | NA | NA | 0.0014 | 1.0000 |
| 2 | H1, H2, H3 | 0.0083 | 0.0083 | 0.0083 | 0.0095 | 0.0095 | 0.0095 | 1.1493 |
| 2 | H1, H2 | 0.0123 | 0.0124 | NA | 0.0135 | 0.0135 | NA | 1.0942 |
| 2 | H1, H3 | 0.0123 | NA | 0.0124 | 0.0135 | NA | 0.0135 | 1.0898 |
| 2 | H2, H3 | NA | 0.0124 | 0.0124 | NA | 0.0134 | 0.0134 | 1.0855 |
| 2 | H1 | 0.0245 | NA | NA | 0.0245 | NA | NA | 1.0000 |
| 2 | H2 | NA | 0.0245 | NA | NA | 0.0245 | NA | 1.0000 |
| 2 | H3 | NA | NA | 0.0245 | NA | NA | 0.0245 | 1.0000 |
Power Considerations
The above illustrates the use of the WPGSD approach to compute bounds at the analysis stage. At the design stage, one can take one of the following 2 options:
The trial can be first designed as if the testing would be done with a weighted Bonferroni with conservative sample size estimate. At the analysis stage, the correlation can be taken into consideration with the WPGSD approach for bound calculation; or
To adjust the sample size downward using the WPGSD approach at the design stage, one can power the study by taking the minimum -value bound for a given individual hypothesis from the WPGSD table (with assumed correlation structure). For example, for of example 1, this is for and for . Then the bounds of () and () can be used to power . This option is not currently supported in the package.
Conclusions
The WPGSD approach provides a unification of previous work on parametric testing in group sequential design. It enabled more complex scenarios and requires attention to consonance and intersection hypotheses. Although detailed closed testing is required, this should not be a deterrent. The approach accommodates various spending approaches and provides more relaxed bounds and improved power compared to the Bonferroni approach.